






更轻,但更好!科大讯飞首发工业级中文预训练模型
近年来,以超大规模模型、海量训练数据、自监督学习准则为特点的无监督预训练模型备受关注。具有高通用性的无监督预训练大模型,结合知识和海量数据进行融合学习,通过提取原始数据的深层表征,实现对于下游任务的通用支撑。
不用重复“造轮子”,预训练大模型强大的泛化能力和优秀的模型效果,让AI模型从开发、部署再到应用有“规”可循,成为实现通用AI技术落地的有效途径之一,也让人看到了AI工业化、规模化落地的曙光。
对AI大规模落地部署应用的期待中,有不少来自各行各业的中小企业,它们也是推进AI走向实用的中坚力量。对于它们而言,无监督预训练大模型的训练和部署代价过于高昂,例如NLP领域预训练模型ChatGPT参数量高达1750亿,使得这项热门技术的产业推广应用困难重重。
目前,预训练模型从比拼参数和数据量级的“秀肌肉”阶段已逐渐进入冷静期,与行业结合的轻量化模型应运而生。在2022年全球1024开发者节上,科大讯飞正式发布了工业级预训练模型,其中包含语音及多模态两个轻量级预训练模型,覆盖不同领域场景、支持多个任务,在参数量上远远小于业界公开模型,但在效果上却在业界表现优异,为预训练模型工业化场景应用交出了一份全新的答卷。

2022全球1024开发者节发布会现场
轻、快、强:直击预训练模型行业应用痛点
以智能语音技术在行业实际应用为例,存在着面临构建多语种、多方言语音系统的数据瓶颈,在高噪环境语音识别、跨信道声纹识别等跨领域场景下的性能损失明显,以及语音合成缺乏对于不同声音属性维度和用户期望音色的灵活定制能力等问题;这些技术问题限制了行业应用的深层拓展,而预训练大模型作为共性关键技术的突破,恰是行业所需。
在此观察基础上,科大讯飞研究院所研发的工业级中文语音预训练模型和工业级多模态预训练模型,聚焦“轻、快、强”三个方面,直击行业应用痛点:
·轻:语音预训练模型小于100M,多模态预训练模型则小于300M,适配云、端等不同场景和不同设备的工业化落地需求;
·快:训练数据覆盖近场、远场、干净、噪声等不同场景,教育、车载、政法等不同领域,在实际应用阶段能够快速适配落地;
·强:语音预训练模型支持语音识别、声纹识别、情感识别等不同任务,多模态预训练模型支持多模态语音识别、多模态情感识别、多模态声纹识别等不同任务,效果在AISHELL2、Voxceleb、LRS3、DFEW、MISP等权威开源数据上均达到SOTA效果。
融合创新:多模态等技术为讯飞工业级预训练模型“添彩”
以行业应用落地为关键导向,兼顾实用性与效果,讯飞此次发布的工业级预训练模型在技术层面融入了多模态等方向的最新成果,也是“轻、快、强”的有力保障。
以多模态预训练模型为例,为了构建一套适用于更多下游任务的多模态统一预训练框架,讯飞研究院从常规的局部唇形信息拓展到了全局面部信息,实现了对表情、话术、身份等表达的面部关联信息的充分利用,从情感、内容、身份属性等层面强化视频和语音支路的信息互补和信息增强,从而匹配更多的下游任务使用场景。
例如讯飞研究院充分利用人脸身份特征与声音身份特征之间的关系,通过一致性约束进行身份信息的强化补充,从而在复杂场景下通过多模态间的信息融合实现更加鲁棒的声纹识别。
同时,为了充分发挥讯飞在有监督层面的技术积累和数据优势,讯飞研究院利用了有监督模型构建了情感码本和内容码本,并对无监督数据提取的高层次特征表达匹配产生指导标签,加快模型的训练收敛,最终实现训练代价下降80%情况下效果依然稳定提升的优异成绩。
在多模态场景下游任务迁移中,因为实际使用场景数据难以获取,有标注训练数据一般只能控制在几千小时的范围内,在这种情况下,多模态预训练的优势更加显著,多模态语音识别、多模态情感识别、多模态声纹识别等任务上,讯飞预训练框架效果平均相对提升了32%。

实力“说话”:讯飞工业级预训练模型应用落地开花
目前,讯飞工业级预训练模型已在多个技术方向实现了行业落地应用,并取得了实打实的好成绩。
在全场景语音识别方面,面向重口音、高噪声、多人对话等全场景语音识别应用,基于讯飞多模态预训练框架实现了包括多模态VAD、多模态增强和多模态识别的功能,在噪声场景较有监督方案效果提升了30%-70%,目前已在车载领域落地,在多点噪声干扰、同向人声干扰等复杂场景依然能够提供良好的交互体验。
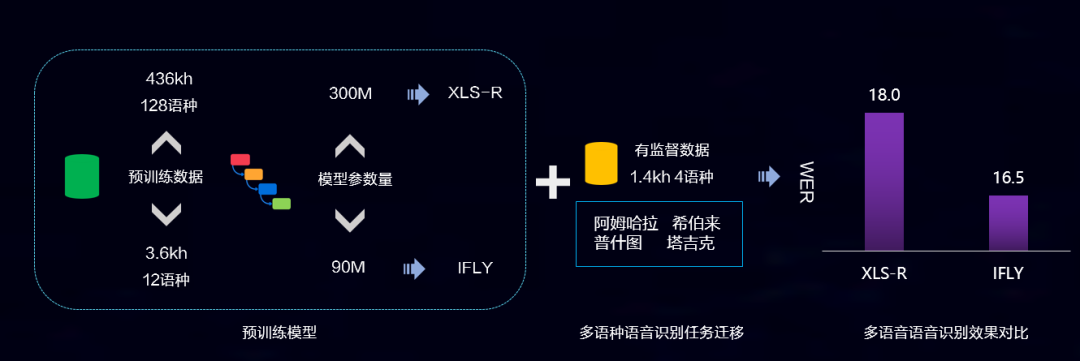
同时,基于讯飞语音预训练框架的多语种、方言语音识别能力,也已经落地翻译机、录音笔等,架起了语言沟通无障碍的桥梁。以阿姆哈拉、希伯来、普什图、塔吉克四个语种为例,和XLS-R预训练模型相比,讯飞的预训练模型在预训练数据需求更少、模型参数量更低的情况下,取得了更好的推广效果。
在细粒度语音情感识别方面,面向不同类别情感定义的情感识别,基于讯飞多模态预训练的情感识别系统,4种情感类别加权平均召回率相对提升15%,目前也已在客服、车载、智慧大屏等场景落地。
在高可控语音合成方面,1分钟个性化合成任务实现合成自然度3.9MOS分,相似度3.7MOS分,自然度接近一般普通人说话的4.0分。实现合成语音在音色、韵律、口音3个属性方向上可连续调节,属性调节方向主观感知准确性达到66%,合成自然度3.6MOS,在讯飞智慧家庭、讯飞电视语音助手、智能车载交互等场景提供更多的用户选择。
人工智能技术的演进和为行业智能化带来的革新,离不开企业和开发者的共同参与投入。讯飞研究院渴望与更多伙伴携手,基于工业级预训练模型加速AI产业化应用落地的步伐,让AI真正能“润物细无声”地浸入各行各业,共享智能化春风下的美景。
想体验讯飞工业级预训练模型的开发者或企业,可登录讯飞开放平台:https://ailab.xfyun.cn/pretrained-model-management

 分享
分享





最新活动更多
- 1 最恐怖的千元机面世!OPPO K12s首发评测来了
- 2 国产手机又大洗牌?小米领跑2025,华为第2,苹果跌至第5
- 3 三星Galaxy S26 Ultra全面曝光:安卓机皇的六大“王炸”升级!
- 4 荣耀400 Pro曝光,看来这次荣耀真的要放大招了!
- 5 iPhone 17 Pro Max全网首曝:苹果十年一遇的颠覆性升级?
- 6 苹果终于对中国用户“上心”了!iOS 18.6曝光亮点全解析!
- 7 iPhone 17系列曝光:苹果这次真的“放大招”了!
- 8 京东大战美团:外卖是外卖,生意归生意
- 9 从「超强夜景」到「一键成片」,影石Insta360 X5轻体验
- 10 2025手机厂商众生相,变局、出海和大电池


发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论